Review incident metrics
Once an incident is resolved, stakeholders can review information and metrics about the incident through the incident console. This allows you to clearly see the incident's key details, such as time to detect, time to acknowledge, and time to resolve, to help perform a comprehensive analysis of an incident's life cycle. Metrics like status by duration and duration by severity are displayed in a graph to provide a visual representation of the information. You can export the data into a spreadsheet at any time during the incident's lifecycle for additional updating, reporting, or filing purposes.
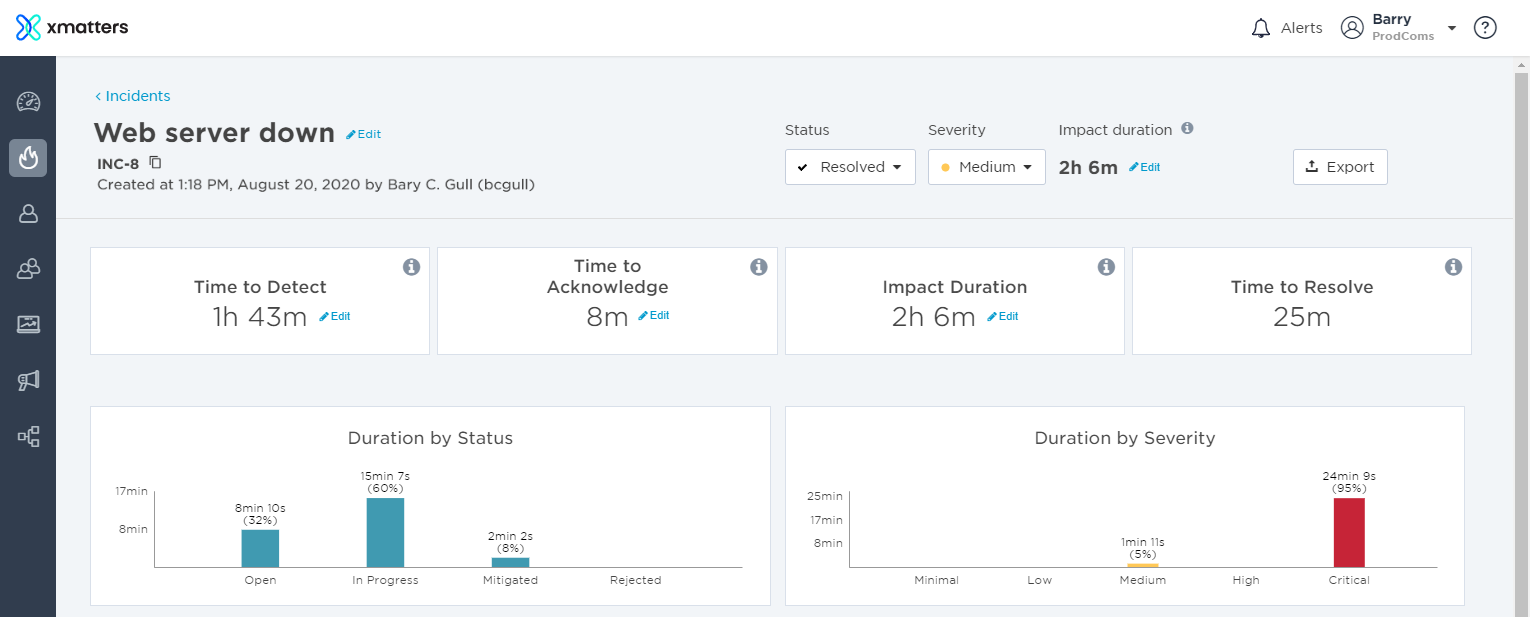
View a resolved incident's metrics and details
To view the console of a resolved incident, click the name of the incident you want to view in the Incidents list. A resolved incident's console displays the incident metrics and other key details. Some details can be edited (such as the incident summary, description, time to detect, and impact duration) to provide a more accurate postmortem report. The console for a resolved incident displays the following details:
The summary appears as the title of the incident on the console and in the Incidents list. This can also be used for categorizing an incident.
The Incident ID is used to reference the incident within xMatters. This is assigned to the incident either by xMatters, or by an automatic process during incident creation.
This displays any services that are identified as being impacted by the incident.
This lists the active and historical incidents that were linked to this incident, along with their corresponding relationship types.
This indicates the incident's current status within the incident resolution process.
Time to Detect is used to identify how long it takes from when a problem is first noticed by a person or monitoring tool, to when the incident resolution process began. This metric is calculated as the time from impact start to when the incident was initiated in xMatters. You can update this by clicking Edit and changing the Impact Start and Detected times to calculate a new Time to Detect
This metric is useful for understanding how quickly teams are able to detect an incident and start the resolution process. If this is longer than expected, it could indicate that your team's processes to identify and initiate an incident need to be reviewed.
Time to Acknowledge is used to determine how long it takes from when the incident resolution process began to when a resolver became engaged in xMatters.
This metric is calculated as the length of time from when the incident was initiated to when the incident's status was updated from 'Open' to another value, or when the first resolver became engaged—whichever happens first. (This includes marking a user as engaged in the incident.) You can update this metric by clicking Edit and changing the Acknowledged time.
This metric helps determine resolver response time. If there is a lag between when a notification is sent and when a user becomes engaged, it may indicate that their devices need to be reconfigured to maximize efficiency. Learn more about managing devices.
The Impact Duration shows how long an incident impacted the service or business. In xMatters, this metric is calculated as the time between when the incident was initiated to when its status was changed to Mitigated (or Resolved, if you bypassed Mitigated). If the impact started before the incident was initiated, you can edit it to reflect this.
This important metric not only helps to determine the efficiency of your incident resolution process as a whole, but also highlights the total degradation your customers experience. It includes the time it takes for teams to detect, diagnose, and repair issues. Ideally, this metric should decrease over time.
Time to Resolve identifies how long it takes from when an incident was detected, to when it was resolved. In xMatters, this metric is calculated as the time from when an incident was initiated to when the incident status was updated to Resolved.
This metric indicates the amount of time teams are spending on repairing issues outside of the total Impact Duration experienced by your customers. Time to Resolve also helps to show how often, and for how long, your services are experiencing issues. If this is an increased amount of time, it may indicate further architecture work needs to be done on your systems.
Duration by Status shows how much time an incident spent in each status (for example, Open, In Progress, or Mitigated), giving you a more detailed picture of the resolution process, how teams progressed, and if there were any unexpected issues. For example, if an incident was Open for a long time before teams start working on it, it could indicate an issue with notifications, on-call scheduling, or your team's workload. Or, if it was Mitigated for an extended period before being fully resolved, it might mean there was additional follow up work that needed to be done to restore the services.
Duration by Severity shows how much time an incident spent in each severity, (for example, Medium, High, or Critical). Use this metric to gain a better idea of how an incident affected your services, and what the peak severity was.
Ideally, an incident's severity level should decrease as its lifecycle progresses. If it doesn't, you can use severity updates to find out why, and evaluate what can be done to avoid similar issues reoccurring during future incidents. Duration by Severity can also be used to monitor and compare different incidents. For example, if multiple higher severity incidents occur over a short period of time, it may suggest that your systems need further analysis to resolve any underlying issues or architectural problems.
The incident description field is used to provide more detailed information, such as the background about alerts leading up to the incident or the affected services.
The roles indicate who is overseeing or performing different tasks in the incident resolution process. As these can be edited during an incident's lifecycle, they can also be used to indicate when and why responsibilities were transferred.
The Tasks section displays a list of all tasks that were created during the incident response process. This list can be filtered to show only active, completed, or rejected tasks. Use this section to review the work carried out during the incident, add any new tasks to complete during the post-incident review, and update the status, assignee, or due date of any ongoing tasks.
The collaboration section includes details of any collaboration channels or applications that were active during an incident's lifetime. Use this section to reference any conversations or updates that happened outside of xMatters.
The Timeline is used to understand how an incident progressed in xMatters. This is displayed as a chronological list of when the incident status or severity was updated, when and how recipients were notified during the incident, and how they responded.
This metric allows you to pinpoint important moments during an incident's lifecycle, see updates on how it progressed, and how resolvers contributed to the incident resolution process.
Export incident
You can export an incident's details as a spreadsheet to perform further data analysis or update stakeholders at any time during its lifecycle.